
Enfin, le problème de la gestion des véhicules est résolu!
Enfin, quand j'aurais implémenté mon design que voici:
En effet, le souci, c'est que, comme beaucoup de gens, j'imagine, j'ai mes idées dans les endroits les plus ésotériques (c'est à dire dans les endroits où réfléchir est la chose la plus intéressante disponible). Je me précipite dès que possible donc sur un papelard pour fixer tout cela au clair.
L'idée principale, ici, c'est que chaque véhicule possède un chemin, et suit ce chemin sans discuter. Le chemin permet donc d'abstraire tout ce qui est en dessous: vitesse max, arrêts nécessaires, position des wagons pour les trains. Lorsque le véhicule arrive au bout du chemin, il peut alors demander au réseau (ferré ou routier, hein, pas le réseau de communications. Quoique...) comment, à partir de sa position actuelle, aller à sa prochaine destination. Le réseau fait tourner son petit Dijkstra (que je vais probablement préférer à A*, mais j'en recauserai), et renvoie un nouveau chemin que le véhicule peut apposer à son chemin courant. Et c'est reparti!
mardi 29 juin 2010
Gestion des véhicules
dimanche 27 juin 2010
Créer ses textures dans Blender
Enfin, j'ai compris comment générer ses textures dans Blender! Le "Node edit" mode, que je n'avais jamais vu auparavant, permet en effet de graphiquement définir de complexes textures procédurales. Tout est expliqué dans cet excellent tutoriel.
Voilà le mur tel que je l'ai généré:
Cela m'ouvre beaucoup d'horizons pour la modélisation des bâtiments. Ces textures donneront je l'espère vie aux bâtiments high-poly, et se laisseront "cuire" gentiment vers le low-poly.
samedi 26 juin 2010
OpenSceneGraph et cache
C'est tout bête, et pourtant il m'a fallu tâtonner un petit peu. Par défaut, OSG recharge chaque ressource en un nœud complétement séparé, même si le fichier est le même. Changer mes 100 gratte-ciel identiques prenait donc environ 10 secondes, et faisait grimper la mémoire à 600 megs.
Perte de temps, perte de mémoire, et c'est exactement pour cela qu'il existe l'objet "osgDB::ReaderWriter::Options". Voyez plutôt:
osg::ref_ptr<osgDB::ReaderWriter::Options>
cachingOptions(new osgDB::ReaderWriter::Options);
cachingOptions->setObjectCacheHint
(osgDB::ReaderWriter::Options::CACHE_ALL);
...
osg::Node * node =
osgDB::readNodeFile("truc.osg", cachingOptions.get());
Et voilà comment passer de 10 secondes à un chargement presque instantané, et de 600 à 280 megs. Facile!
lundi 21 juin 2010
Des grattes-ciel

Voilà 50 grattes-ciel sur mon terrain. Les modèles ont été faits sous Blender, et ont environ 5600 faces chacun, ce qui est beaucoup! Au rendu, OSG ne s'en sort pas trop mal, puisqu'il m'en affiche une bonne partie tout en restant au dessus des 100 images par seconde.
C'est typiquement le genre de situation qui va nécessiter des niveaux de détails! A très courte distance, le bâtiment est détaillé juste comme il faut. Mais de loin, il va falloir sérieusement réduire le nombre de faces. La solution que je compte suivre est de créer une version peu détaillée du bâtiment (pas beaucoup plus qu'un bête cylindre!), et de "cuire" les normales du modèle détaillé vers une texture pour le modèle peu détaillé. L'on peu ainsi espérer un rendu à peu près équivalent à distance, avec peut-être une centaine de polygones, au lieu de plusieurs milliers.
Au passage, les défauts de rendu liés au crénelage sont tristement visibles. Je compte pour le moment attendre que wxWidgets fournisse le support pour l'anti-crénelage, et si j'en ai besoin plus tôt, j'insérerai une surface SDL ou SFML pour faire le boulot.
samedi 19 juin 2010
Ça fait beaucoup de flèches

C'est 100.000 flèches qu'OpenSceneGraph m'affiche. Bon, d'accord, ça rame :) L'ensemble de l'exercice était plutôt une tentative pour pousser le moteur dans ses retranchements, et s'il me fallait vraiment en afficher autant, j'aurais recours à d'autres méthodes (imposteurs?).
C++0x - Default et delete explicites
Ce n'est pas vraiment une révolution, mais c'est une fonctionnalité plutôt agréable de C++0x: la possibilité de spécifier explicitement ses constructeurs par défaut, ou leur absence.
La syntaxe est des plus simples, voyez donc mon entity factory:
class EntityFactory
{
public:
EntityFactory() = default;
EntityFactory(const EntityFactory &) = delete;
EntityFactory & operator=(const EntityFactory &) = delete;
virtual ~EntityFactory() = default;
};
Cette signature indique que le constructeur par défaut "est" le constructeur par défaut, qu'il n'y a pas de constructeur par copie, pas d'assignement, et enfin que le destructeur par défaut "est" le destructeur par défaut.
La suppression du constructeur par copie et de l'assignement se faisaient généralement soit manuellement, en les déclarant privés (ce qui prenait un poil plus de place), ou en dérivant de la bonne vieille boost::noncopyable, ce qui prenait plutôt moins de place. La méthode "A la mano" est à mon avis la moins bonne, puisque la moins explicite. Entre boost et le delete C++0x, mon cœur balance, il faudra donc voir à l'usage.
Par contre, la possibilité de définir le destructeur virtuel par défaut est vraiment bien. et évite d'avoir à se farcir un corps de méthode vide.
Attention cependant! La règle qui dit que définir un constructeur supprime le constructeur par défaut implicite est encore valide. Ansi, ce petit programme:
class A
{
public:
A(const A &) = delete;
A & operator=(const A &) = default;
};
int main()
{
A a;
return 0;
}
ne fonctionnera pas comme prévu, et jettera le message "error: no matching function for call to ‘A::A()’". En effet, définir ne serais-ce que l'absence du constructeur par copie supprime le constructeur par défaut implicite.
Le programme correct est donc:
class A
{
public:
A() = default;
A(const A &) = delete;
A & operator=(const A &) = default;
};
int main()
{
A a;
return 0;
}
lundi 14 juin 2010
Et encore des en-têtes gcc précompilées
J'étais plutôt satisfait de mes gch, mes fichiers d'en-têtes pré compilées, mais au fur et à mesure que le code devient plus gros, et avec l'ajout de la compilation optimisée, je me heurtais de plus en plus souvent à la vitesse de mon disque.
En effet, ces fichiers d'en tête pré compilés, les fameux gch, prennent une place éléphantesque, surtout si on génère les informations de debug. Une en-tête contenant quelques fichiers STL et Boost pourra monter facilement à 100 megs. Si l'on rajoute par exemple wxwidgets pour la GUI, Open Scene Graph pour la 3D, OpenAL pour le son, on dépassera facilement les 300 megs.
Ayant initialement créé un fichier pré compilé pour chaque bibliothèque et application, la plus grande partie du build était passée à charger ces fichier gigantesques en mémoire. Une fois que les fichiers y sont, la compilation est rapide, car ils restent en cache pour la suite. Mais la bibliothèque suivante utilisant un autre ficher, l'on se retrouve à relire des centaines de megs. Au total, 15 bibliothèques et 2 builds (debug et optimisé) plus tard, c'étaient plusieurs gigs à chaque fois, et mon CPU restait désespérément à plat pendant que le disque turbinait.
La solution, relativement évidente une fois que le problème est clair, est de n'utiliser qu'un seul fichier d'en tête pour tout le monde. Sauf que je ne veux pas que le serveur, par exemple, réclame de se lier aux bibliothèques de son, juste parce qu'il référence le son via l'en-tête partagée.
J'ai donc créé un nouveau projet "gch", lequel contient 3 fichiers d'en-tête: Basic.h, Client.h et Server.h, lesquels contiennent les inclusions nécessaires aux trois types d'applications. Je n'ai plus qu'à référencer le bon fichier depuis chaque bibliothèque / exécutable, et la différence est tout à fait remarquable: mon CPU est maintenant à fond, et je profite pleinement de la compilation parallèle. Quelques tests confirment qu'une compilation prend maintenant 2 minutes et atteint les 3.5 gigs de RAM, contre 5 minutes et seulement 2.5 gigs de RAM sans la pré-compilation.
samedi 5 juin 2010
C'est comme si c'était fait!
C'est le truc avec les abstractions: quand elles sont bien faites, tout se met à marcher tout seul. Voilà donc un rail qui ressemble enfin à un rail.
(Même si la musique de Michel Legrand sur "The Go-Between", reprise dans l'émission "Faites entrer l'accusé", a beaucoup aidé).
Sniffe moi ce rail!
C'est très moche, mais les principes fondamentaux sont là: je peux afficher mon rail. Je suis satisfait de l'abstraction autour de mes sections: une section abstraite renvoie sa matrice de transformation pour une longueur donnée, et j'en dérive les sections droites et courbes. C'est là que mes vieux souvenirs sur les matrices de changement de base se sont rendus utiles!
Je peux donc diviser ma section abstraite et appliquer la transformation en chacun des points que j'ai choisi à la traverse, et au profil de mon rail. J'enfile ensuite les profils, et créé la boite correspondante.
Une fois que le rail aura la bonne taille, et tournera gentiment sur ses traverses, il va falloir trouver une texture qui ne soit pas trop moche, et tripatouiller les reflets pour obtenir un effet métallique.
jeudi 3 juin 2010
Courbes
Enfin, mes traverses suivent une voie courbée. Magique!
Le premier essai était plutôt bizarre:
Mais après quelques inversions aléatoires de produits vectoriels, les traverses s'alignent beaucoup plus gentiment: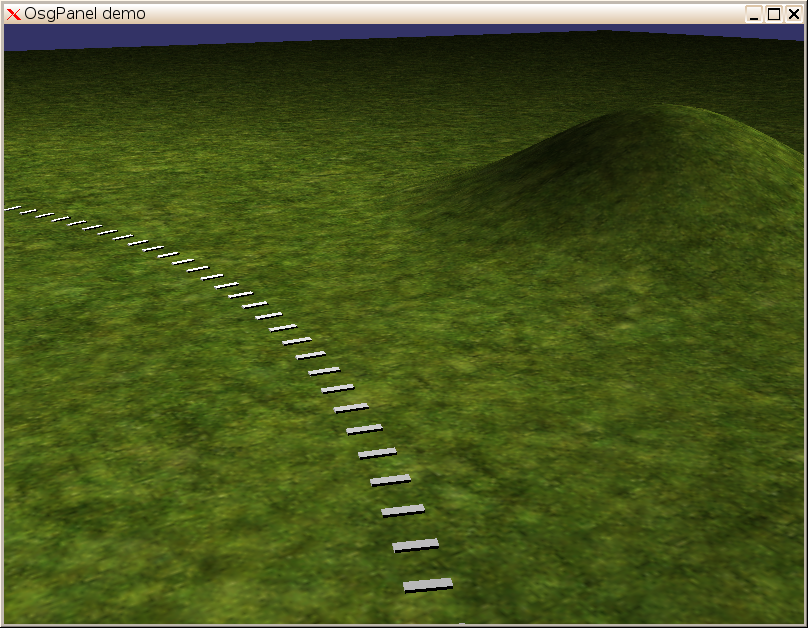
C'est pas tout, mais maintenant, il va falloir y mettre des rails!
mardi 1 juin 2010
Réparation du build optimisé
Ayant enfin compris comment gérer les builds multiples dans OMake (en l'occurrence, un build debug et un build optimisé), je me suis décidé à réparer la compilation de manière à ce qu'elle fonctionne avec l'option -O3, qui causait l'erreur suivante:
dereferencing type-punned pointer will break strict-aliasing rules
Il s'agissait de fait d'un bout de code un peu sale pour sérialiser des doubles, passant par une coercition directe d'un pointeur vers double dans un pointeur vers entier non signé 64 bits. Le compilateur se plaignait donc à juste titre qu'une telle conversion risquait de foirer à cause des problèmes d'alignements. L'on peut se débarrasser du message d'erreur en passant à g++ le flag -fno-strict-aliasing, aux dépends de l'optimisation et de la propreté générale du code.
M'inspirant de cette page, j'ai donc écrit une fonction de conversion d'un double vers un entier 64 bits, qui caste ces deux types vers des pointeurs char non signés (opération toujours valide), et qui fait la copie octet par octet.
uint64_t dtou64(double input)
{
uint64_t output;
unsigned char * dst = reinterpret_cast(&output);
unsigned char * src = reinterpret_cast(&input);
std::copy(src, src + sizeof(input), dst);
return output;
}
Une fois cette fonction et son symétrique écrits, il était trivial de compléter le code de sérialisation et de se débarrasser du message d'erreur.